zepto.js.v1.0 源码解读-zepto.js-01
一直以来都有一个问题困扰着我,那就是我什么时候才能写出一个好用的html的dom元素选择器。 假如就只是单单把 document.getElementById || document.getElementByTagName … 封装起来的话,没有多大的意义。可用的扩展功能较少,没有zepto,Jquery灵活。 为了一探究竟,我就从网上下载了zepto源码下来研究。 我一看这就一个js文件,看样子要去github上确认一下。于是使用命令
git clone https://github.com/madrobby/zepto.git
克隆了一份到本地,打开一看原来zepto本来是有很多个模块组成的。
zepto常用模块
-
zepto.js这个是核心模块
-
ajax.jsxhr模块
-
event.js事件模块
-
form.js表单验证
-
touch.js移动端事件
做过移动端页面的同学应该对它都不会陌生。我记得好像淘宝的商品详情页好像就是缩水版的zepto,也就是只包含了部分模块。 感兴趣可以去看看。
今天就来分析zepto的选择器源码是如何实现的吧。
zepto.js模块
那么这么多函数,从何下手呢。咱们就从用的最多的 $ 下手。 纵观全局,先分析 $ 是怎么来的。
var Zepto = (function() {
...... //省略代码
zepto.Z.prototype = Z.prototype = $.fn
zepto.uniq = uniq
zepto.deserializeValue = deserializeValue
$.zepto = zepto
return $ // $ 这个就是zepto暴露到全局的唯一对象
})()
window.Zepto = Zepto
window.$ === undefined && (window.$ = Zepto)
会发现整个Zepto其实是一个闭包的自动执行函数,对外界暴露的唯一的就是 $,就是那一条return $.
假如window对象的 $ 没有被占用就将 Zepto赋值到window对象的$上。
不管我们在js 里面通过$(serlector [,context]) 还是 Zepto(selector[,context])进行调用,都会调用Zepto内部的$.
Zepto内部的$
现在我们进如Zepto内部,看一下$是一个什么对象。
$ = function(selector, context){
return zepto.init(selector, context)
}
原来Zepto内部还有一个zepto对象(首字母小写),现在终于明朗了。$其实是对zepto.init函数的封装。
也就是说 $(serlector [,context]) || Zepto(selector[,context]) ,其实就是执行的zepto.init函数。
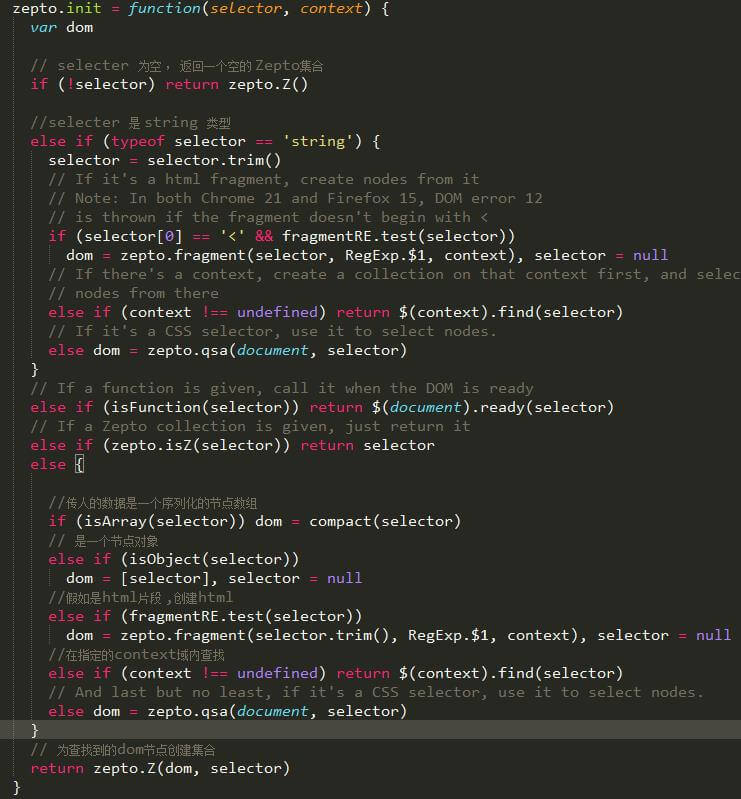
下面我们进入zepto.init函数去看看 ,为了看清楚我这里特意截取图片。
下面是我对这个函数的流程简化图。
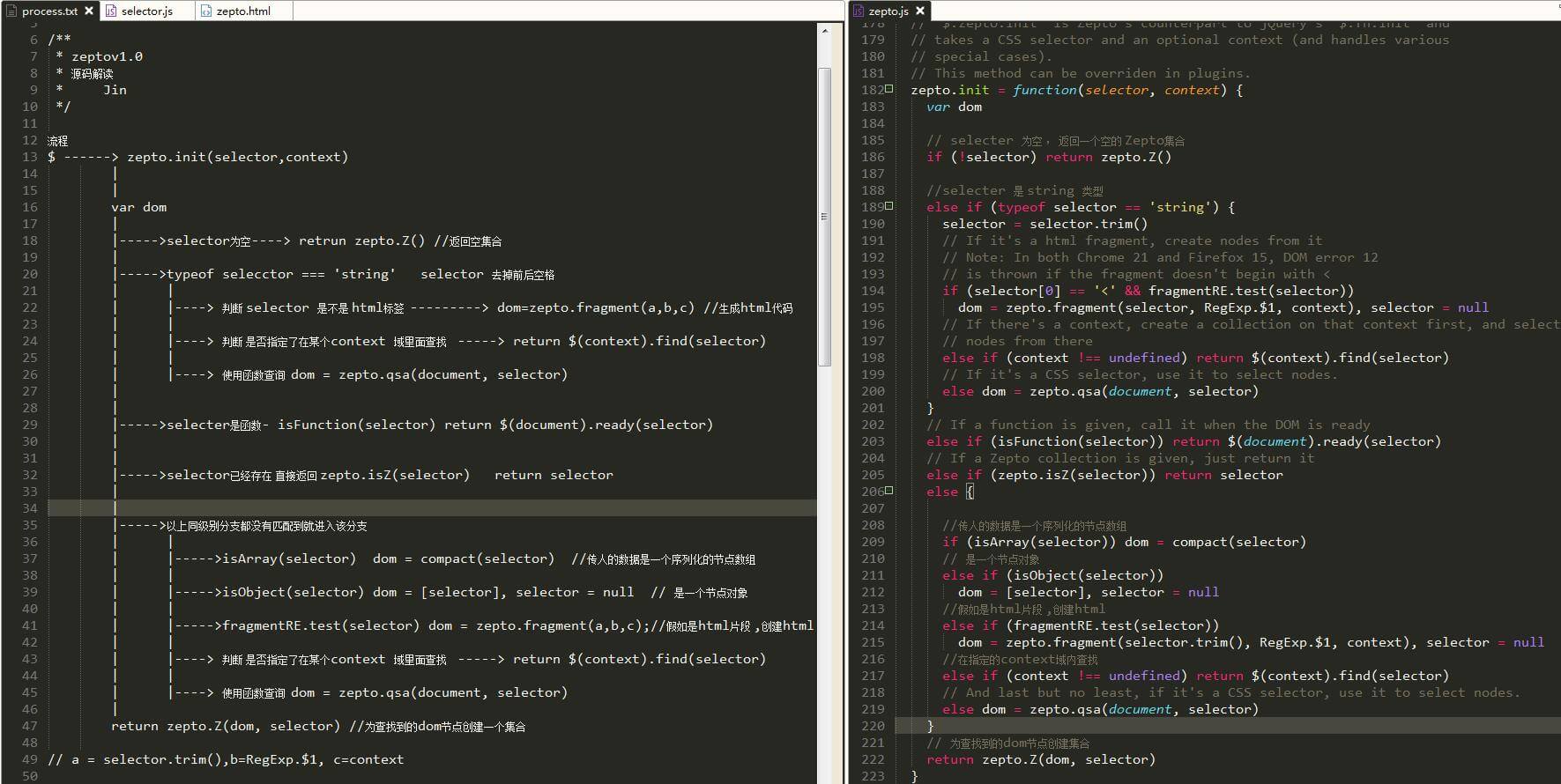
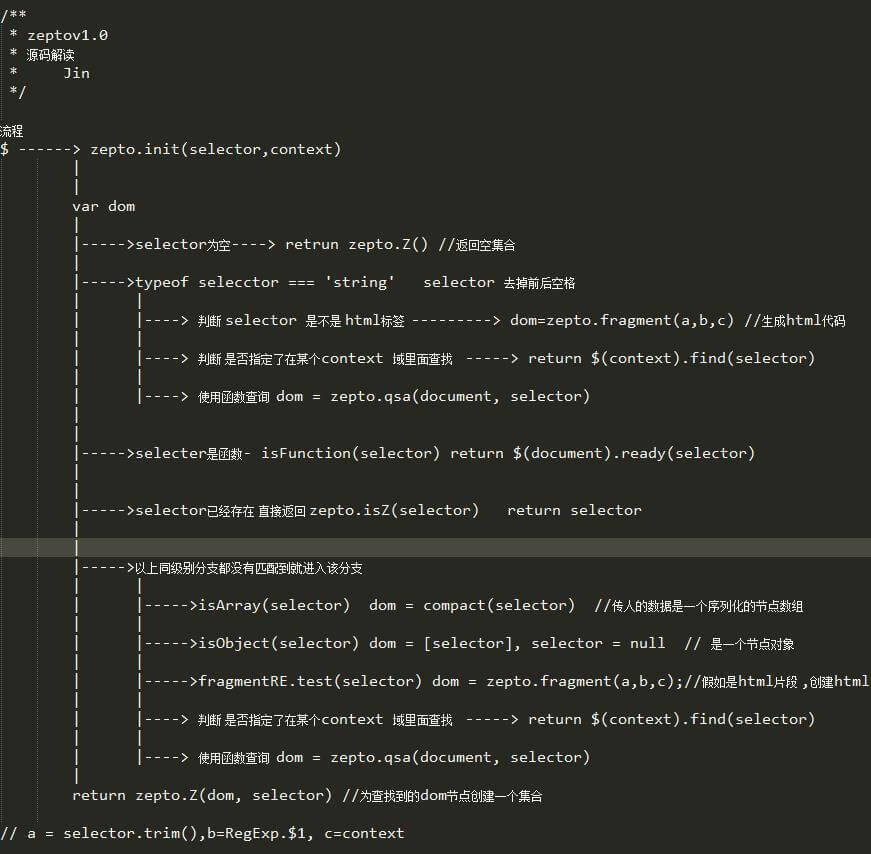 再来一张对比图,看不清自行拉到新窗口看。
再来一张对比图,看不清自行拉到新窗口看。
可以知道zepto.init函数将情况分为了 5种
-
selector为空 及什么都不做,返回空集合
-
selector是字符串
-
selector是函数
-
selector是zepto集合
-
- 其他
不管是哪一种情况返回的都是zepto集合,也就是说都会执行一次zepto.Z([dom,selector])函数,或原来执行过一次。这样返回的数据将是统一的格式。 下面我们就在第一种情况中讨论zepto.Z函数。
1.selector 为空
selector为空,是直接执行 zepto.Z() , 并返回。
function Z(dom, selector) {
var i, len = dom ? dom.length : 0
for (i = 0; i < len; i++) this[i] = dom[i]
this.length = len
this.selector = selector || ''
}
zepto.Z = function(dom, selector) {
return new Z(dom, selector) //新建对象 ,防止使用同一个对象产生错误,使用new
}
这个函数其实就是对获取到的dom元素等做一下格式化,假如dom是存在的那就将所有的都赋值到this对象上。
为空,那么最后得到的就是一个空的对象 : [] , 命令格式: $()。
2.selector为字符串
这中情况下又分了3中情况:
-
- 传人的是html
-
- context不为空,在指定的域中查找
-
- 调用选择器在document中查找
不管是哪一种情况,对字符串进行前后多余空格删除是必须的。
2.1传入的是html#
e.g: $('<div>传人html</div>')
zepto会认为这样做的目的是生成dom元素。那么这样的操作其实等价于:
//$('<div>传人html</div>')
var div = document.createElement('div')
div.innerHTML = "传人html"
return div
这只是一个最简单的列子,如果要作为一个灵活的功能模块的话,还需要进一步的优化和扩展,比如如何判断传人的是html标签. 我们知道html标签就只有两种情况 <tag/> 或 <tag></tag>,那么传人的html可能就是这两种情况的互相嵌套。
那么就可以通过正则表达式匹配出入的是否符合html标签标准
// html标签判断
fragmentRE = /^\s*<(\w+|!)[^>]*>/
上面这个正则表达式的意思是:
// html标签判断
^\s* : 表示从行首匹配 0-n次的空白符
<(\w+|!)[^>]*> : 表示匹配以 < 开头和>结尾的字符串,并且必须匹配一个可以组成单词的字符或!开头,不匹配> 0-n次
你可能会发现为什么没有匹配</tag>,其实没有必要了,因为只要匹配出它是标签即可创建了。而且zepto也只匹配了最外层的tag,并没有匹配所有的这是为什么。 所以上面的也是可以简写的。
// html标签判断
if (selector[0] == '<' && /^\s*<(\w+|!)[^>]*>/.test(selector)){
dom = zepto.fragment(selector, RegExp.$1, context), selector = null
}
// RegExp.$1 等价于 匹配到的tag
// e.g: $('<img>') --> RegExp.$1 == img
zepto交给了zepto.fragment()去处理,也就是说上面的js只要保证最少有一个<tag>即可。
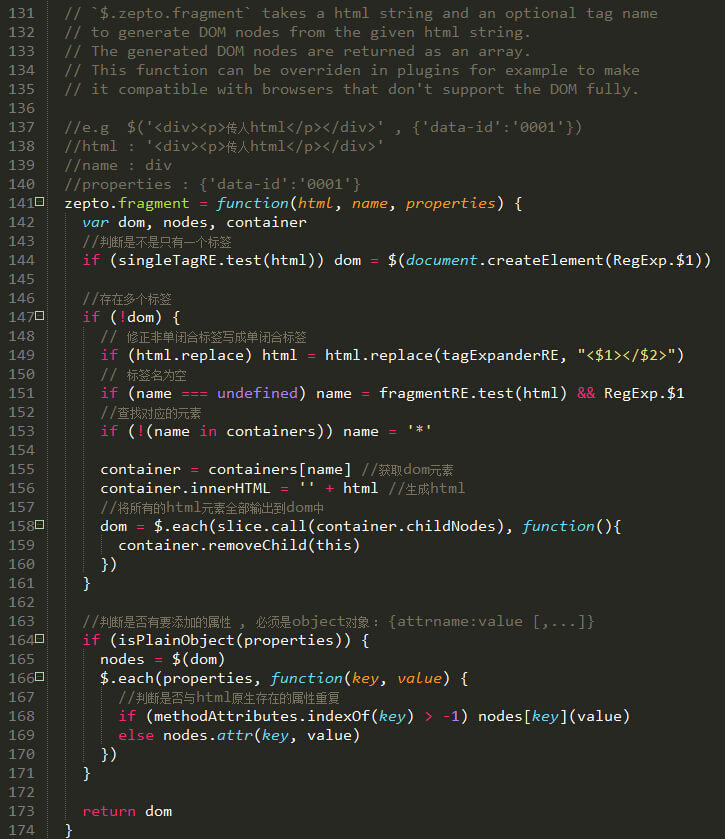
函数的注释也说得很明白:根据html字符串和标签名生成dom节点数组并返回。 这个函数也是可以被重写的,并且这个函数不完全兼容浏览器。
再来看看对应的正则判断:
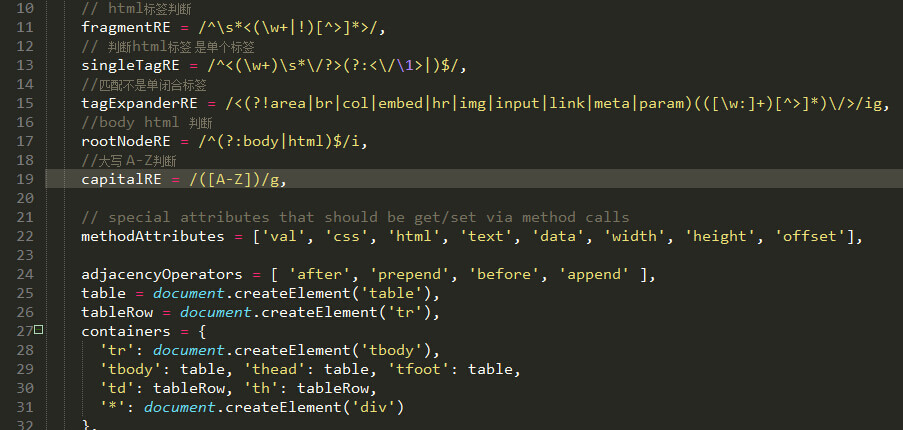
最后我在拓展一下,将元素复制到dom这一步
//将所有的html元素全部输出到dom中
dom = $.each(slice.call(container.childNodes), function(){
container.removeChild(this)
})
//等价于
var arr = [].slice.call(container.childNodes);
dom = arr; //只不过zepto为了让container恢复原始状态而使用了上面的方式
另外的一个就是如果带有属性传人的话,也就是properties 对象不为空时。添加属性是为每一个dom元素都添加的。也就是dom数组里的所有元素都添加。
2.2context不为空,在指定的域中查找#
虽然代码看着很简单,其实这个是最复杂的一条分支。因为context变量是可以有几种形式存在。比如:对象,字符串。
那么当使用
$(context).find(selector);
//是等价于
var dom = $(context);
dom = dom.find(selector);
上面这种格式来获取dom元素时,其实调用了2次zepto.init,比一般的dom获取多了一次。
$.find()函数写的非常的简洁:
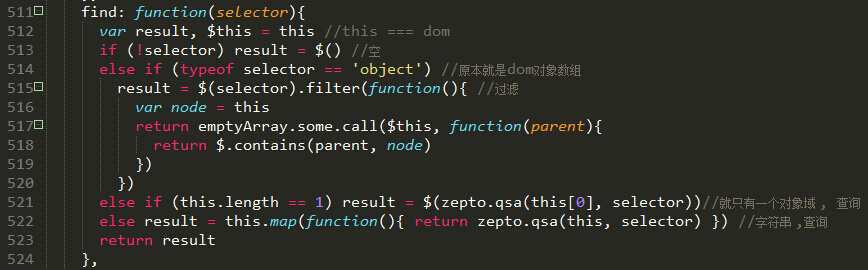
我们看到的上面4中情况可能就是第2中情况比较难以理解,其实不然。 第二种情况是传人的参数都是dom对象数组——判断selector数组对象是不是有属于context数组对象的子元素。 现在我们来分析一下他是如何实现过滤获取到最后符合条件的结果的。
//过滤不符合条件的dom节点
//e.g : dom = dom.find(selector);
// $this = dom
result = $(selector).filter(function(){ //过滤
var node = this
return emptyArray.some.call($this, function(parent){
return $.contains(parent, node)
})
})
这里面牵涉到3个函数,filter,some,contains。现在我们分别来看这3个函数。
//filter函数
filter: function(selector){
if (isFunction(selector)) return this.not(this.not(selector))
return $(filter.call(this, function(element){
return zepto.matches(element, selector)
}))
}
我们来看看some函数的定义:只要有数组元素满足f的要求就返回true,否则返回false。

那么我们就可以推断出 $.contains函数就是判断 selector 是否是 dom的子节点。
//$.contains函数 通过它可以判断某个节点是不是另一个节点的后代
$.contains = document.documentElement.contains ?
function(parent, node) {
return parent !== node && parent.contains(node)
} :
function(parent, node) {
while (node && (node = node.parentNode))
if (node === parent) return true
return false
}
那么你可能会发现,我为什么没有先讨论filter,而是先讨论的some函数和contains函数。
因为filter函数里面嵌套这这两个函数,从运算来说必须先得这两个函数执行完了,filter函数才会返回。
其实真正的filter函数他是如何完成筛选的我们还不知道,我们只知道了[].some()函数返回了true | false.
filter 真正是什么函数还得看它内部的实现。
上面我已经给出了filter函数的源码。就两种情况:1:传人的是函数,2:不是函数。这里我们只讨论传人函数的情况。
也就是直接嵌套调用了2次$.not()函数。 从not函数的字面来看就是 不是的意思,那两次不是就是是的意思。
和数学里面 负负得正类似。
//$.not 函数
function(selector){
var nodes=[]
if (isFunction(selector) && selector.call !== undefined)
this.each(function(idx){
if (!selector.call(this,idx)) nodes.push(this)
})
else {
var excludes = typeof selector == 'string' ? this.filter(selector) :
(likeArray(selector) && isFunction(selector.item)) ? slice.call(selector) : $(selector)
this.forEach(function(el){
if (excludes.indexOf(el) < 0) nodes.push(el)
})
}
return $(nodes)
}
因为传人的是函数所以not函数会执行if分支,第二次是dom数组所以执行else。
现在整个流程基本跑通。那现在我们就是要把整个流程在理清楚就可以了。
//filter函数执行过程简单化
var result , $this = this , nodes =[];
for ( var idx in $(selector) ){
if ( !isBlong($this , idx) ){ //判断idx是否属于 $this的子元素
nodes.push(idx);//得到不属于
}
}
function isBlong(parants , node){
for ( var parent in parents ){
if ( $.contains(parent , node) ){
return true;//匹配到了
}
}
return false //所有的node不属于任何一个dom里的子节点
}
for ( var idx in $(selector) ){
if ( nodes.indexOf(idx) < 0 ){ //把不属于dom子节点的排除掉,留下属于的
result.push(idx);
}
}
return $(result);
你可能会发现,其实是没有必要怎么复杂,只要把isBlong函数前的!去掉就可以得到属于dom的子元素了,最后的for循环就可以不用了。而zepto是为了简化代码,调用了两次not函数。
这是相同的道理。
//filter函数终极版
var result , $this = this;
for ( var idx in $(selector) ){
if ( isBlong($this , idx) ){ //判断idx是否属于 $this的子元素
result.push(idx);//得到属于
}
}
function isBlong(parants , node){
for ( var parent in parents ){
if ( $.contains(parent , node) ){
return true;//匹配到了
}
}
return false //所有的node不属于任何一个dom里的子节点
}
return $(result);
这就是find函数执行第2种情况的最终代码。
2.3调用选择器在document中查找
我相信到了很多人都不会对这个感到陌生。因为这也是我们日常工作用的最多的。 装B的,看看能看得懂不。
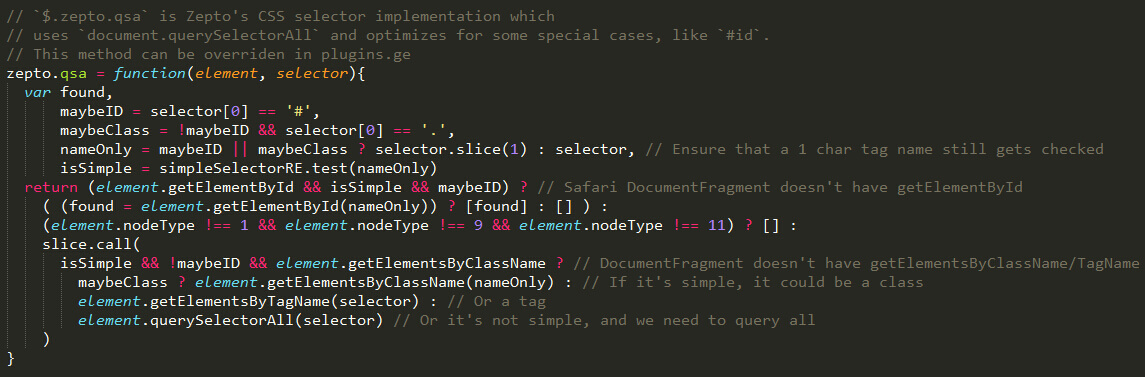
先看看注释说了些什么。zepto.qsa函数是CSS选择器的实现,主要用 document.querySelectorAll方法,以及对像 #id这样的,使用一些优化方法。 这个函数是可以被重写的。 zepto对这个函数进行了优化,所以看起来比较的费劲。这里我做一下还原。
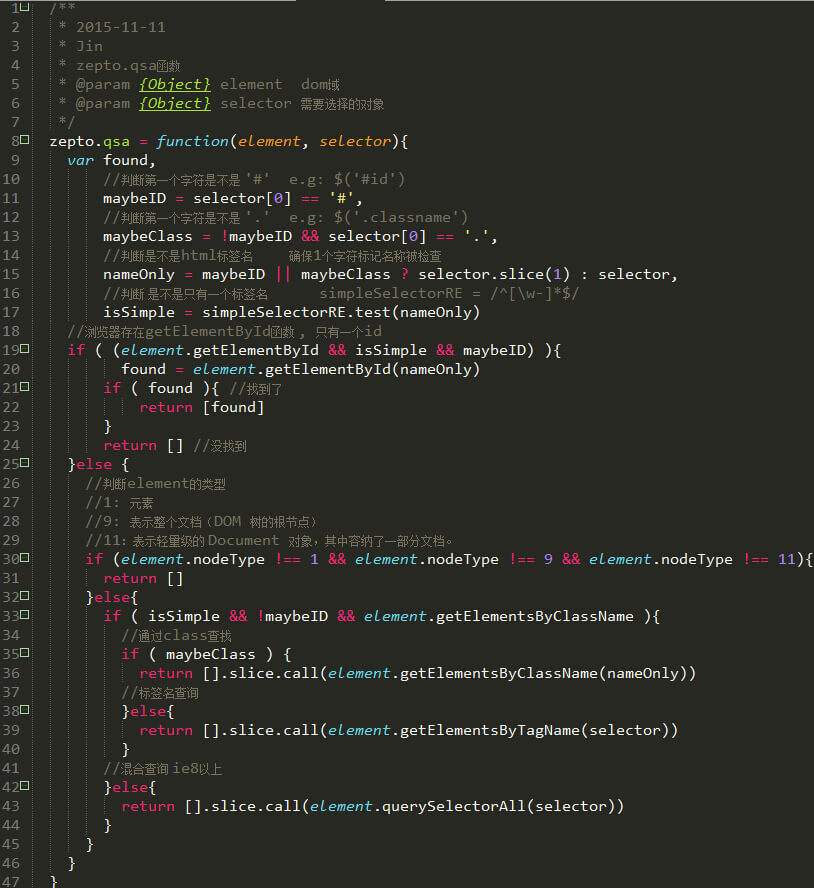
是不是瞬间感觉lower好多。zepto有个好处就是你能跟着他的函数往下走,不像jquery非常复杂。现在回过头来看看就知道zepto为什么把函数压缩优化了吧。既占空间又感觉不上档次。
zepto.qsa主要把id和class混合存在的情况都交给了querySelectorAll函数.其他的判断就是将一些特例单独处理。就比如:对于单个id我们可以使用document.getElementById一样。 你要是很懒,全部用 document.querySelectorAll 吧。
zepto在selector.js模块中对该函数进行了重写,感兴趣的可以去看看。
到这里selector为字符串的时候讨论完了。
3.selector 是函数
selector 为函数
//$(selector)
//e.g
$(function(){
console.log('ok')
})
上面是一个最简单的调用方法,就是传人一个函数,那么zepto是通过调用 * $(document).ready(selector)*函数执行的。
ready: function(callback){
// need to check if document.body exists for IE as that browser reports
// document ready when it hasn't yet created the body element
if (readyRE.test(document.readyState) && document.body) callback($) //ie
else document.addEventListener('DOMContentLoaded', function(){ callback($) }, false)
return this
}
看了就明白了,就一句话:dom加载完后执行这个函数。
最后的两种情况就没什么好讲了。
4.selector 是zepto集合
直接返回.
5.其他
相当于在调用一次zepto.init。你看源码就知道。其实第5中情况就是前面所有情况的集合。
最后要对返回的dom对象数组进行什么操作,其实就很简单了。只要在 $上绑定函数就可以了。 这就是为什么zepto代码会很多,就是因为这些扩展函数的原因哦。