【译】Node.js之对象流(Stream)权威指南
Node.js的Srtream具有强大的功能:你可以使用异步的方式处理输入和输出,可以根据所依赖的步骤来对数据进行转换。本教程中,我将带你熟悉理论,并教你如何灵活使用Stream对象,就像使用Gulp一样。
当我在写一本名为 《前端工具之Gulp,Brower和Yeoman》 的书时,我决定不仅要展示API和使用案例,还需要关注以下的概念。
你要知道特别是在JavaScript中,工具和框架的更新换代比你为它们注册域名和创建Github团队的速度还要快。例如Gulp.js,最重要的一个概念是流!
约50年的流
在Gulp里,你想要读取一些文件的数据转换为指定的数据输出,加载一些JavaScript文件并打包成一个文件。这些操作Gulp的API已经提供了一些方法来读取,转换,和写入文件,所有的这些方法都是基于流来实现的。
在计算机中流是一个很老的概念,,源自1960年代早期Unix。
“流是一个数据随着时间序列从源到目的地的过程。“ @ddprrt
数据源的类型是多样化的:文件,计算机内存或者像键盘,鼠标之类的输入设备。
流一旦被打开,数据就会从原点开始分割成一块块的小的数据进行传输然后消费。输入一个文件,每个字符或者字节都会被读取一次;键盘输入,每个按键将传输数据流。
最大的优势在于一次加载所有数据,理论上,输入可以无限输入的完全没有限制。
来着键盘的任意一个输入都是有意义的 —— 为什么你应该通过键盘输入控制电脑关闭输入流?
输入流统称为可读流,这意味着它们从原点读取数据。另一方面,有输出流和终点;它们可能是文件或者某一段内存,一般输出设备可以是命令行,打印机,或屏幕之类的。
它们统称为输出流值,意味着它们存储来着流的数据。下图说明了流是如何工作的。
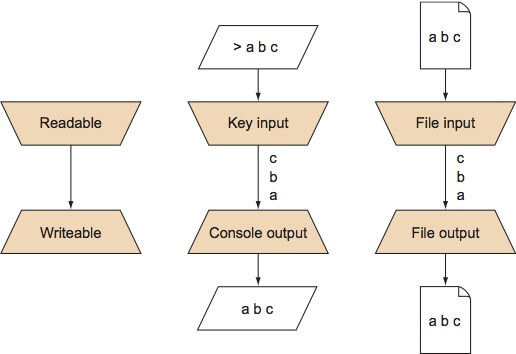
数据是由一组可用的元素组成的序列(就像字符或者字节)。
可读流可以来自不同的来源,例如输入设备(键盘),文件,内存里面的数据。可写流可以任意的终点,例如文件和内存,以及众所周知的命令行。
可读和可写流可以互换:键盘输入可以保存在文件中,命令行输入可以作为文件的输入流。
它不仅可以有无尽的输入,而且你可以结合不同的可读和可写流。关键的输入可以直接存储到一个文件中,或者你可以通过命令行和打印机打印文件。接口保持不变,无论来源或目的地是什么。
在Node.js最简单的涉及到把流的从标准输入转换到标准输出的程序例子,使用控制台:
process.stdin.pipe(process.stdout);
我们把我们的可读流(process.stdin)把它转换到可写流(process.stdout)上。在这之前,我们可以把任意的流内容从任意的原点转换到任意的终点。
就以request包为例,我们可以使用它向指定的URL发送http请求。为什么不从网上来取一些页面并且使用process.stdin把它打印出来?
const request = require('request');
request('https://fettblog.eu').pipe(process.stdout);
使用控制台输出一个HTML确实不怎么有用,但是使用它转换到一个文件却是网络利刃。
转换数据
流不仅适合用来在不同的原点和终点之间传输数据。
流一旦打开数据只会暴露一次,开发者可以在数据到达终点之前进行转换数据,最简单的例子就是把一个文件所有小写字符转换为大写字符
这是流其中的一个最大的优势所在。流一旦打开你就可以一块块的读取数据,你可以在程序的不同位置进行操作。下图说明了这个过程。
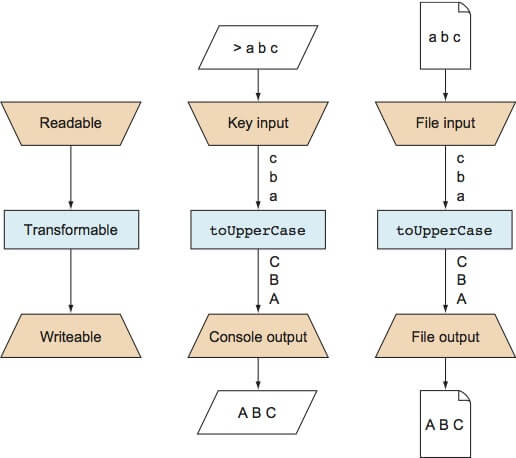
对于修改数据,你只需要在输入和输出之间添加对应的程序转换代码块。
本例子中,你拿到来自不同原点和渠道的输入数据并且使用toUpperCase进行转换。这个会把小写字符转换为它们对于的大写字符。这个函数一旦定义,就可以在不同的输入原点和输出重复使用。
下面,我定义了一个toUpperCase的函数——用来转换任意字符对应的大写字符。创建这个函数有多种方式,但是我是Node.js流封装库像through2之类的超级粉丝。他们已经定义一个好的包装,可以轻松的创建一个转换体:
const through2 = require('through2');
const toUpperCase = through2((data, enc, cb) => { /* 1 */
cb(null, new Buffer(data.toString().toUpperCase())); /* 2 */
});
process.stdin.pipe(toUpperCase).pipe(process.stdout); /* 3 */
- 1.
through2库绑定第一个参数为函数。 这个函数用来传递数据(默认为Buffer实例),传入一些字符编码和一旦我们传入回调函数我们就可以在转换完成之后进行调用。 - 2.通常,在Node.js流里面,我们传递
Buffer类型的数据流。可以来自process.stdin的数据,在我们按下回车键之后。来自一个文件,这实际上可以任何东西。我们转换当前Buffer为字符串,把小写转换为大写,然后转换为Buffer再次输出。回调函数有2个参数,第一个参数是错误信息。如果你没有对end事件进行监听来捕获错误,流将崩溃程序会由于异常而退出。没有异常第一个参数会返回null。第二个参数是转换的数据。 - 3.我们可以传递我们可读的输入数据到这个转换函数。转换好的数据传递到我们的可读流。
这是完全在函数式编程的路子。我们可以重复使用这个函数来转换不同输入或输出,只要它是可读流。我们不需要关心输入源或输出。同时,我们并不局限于一个单一的转换。我们可以同时链式调用多个转换就像这样:
const through2 = require('through2');
const toUpperCase = through2((data, enc, cb) => {
cb(null, new Buffer(data.toString().toUpperCase()));
});
const dashBetweenWords = through2((data, enc, cb) => {
cb(null, new Buffer(data.toString().split(' ').join('-')));
});
process.stdin
.pipe(toUpperCase)
.pipe(dashBetweenWords)
.pipe(process.stdout);
如果你熟悉Gulp,对上面的代码应该会有映象。很简洁,不是吗?然而,Gulp流需要特别注意的不同点是:不会传递Buffer类型的数据,我们使用的是简单的,原生的JavaScript对象。
流对象
在标准流里,通常看到的文件只是可能作为一个真实数据的输入源,要处理的数据。流一旦打开,文件的所有信息像路径或文件名等这些信息也会被传递。
在
Gulp里,你要处理的内容不仅是一个或多个文件,你也需要文件名以及文件系统里面的真实文件。
试想一下现在有20个JavaScript文件需要进行压缩处理。你需要记住每个文件的文件名病情需要保证每个文件的数据都能正确的保存到对应的输出文件中(一些压缩文件)。
幸运的是,Gulp同时为你创建一个新的输入源和一个对你当前数据流非常有用的数据类型:虚拟文件对象。
Gulp中流一旦打开,文件的所有原始信息,物理信息都会被打包到一个虚拟的文件对象中并且保存到虚拟文件系统中,或者Vinyl中,好让Gulp中相应的组件进行调用。
Vinyl对象,文件对象是你的虚拟文件系统,内容包含两种类型的信息:根据文件名称和路径可以定位文件的位置,以及流里面传输的文件内容。虚拟文件保存在计算机内存中,这样处理数据时更加的快速。
通常所有的修改可能最终都会保存到硬盘上。把所有的东西都放在内存中进程之间在处理数据的时候就不用再执行昂贵的读写操作了,保证Gulp上下文迅速切换。
在内部,Gulp使用对象流去一个个的加载文件到处理管道中。对象流和普通的流行为类似,而不是Buffer和String类似。
我们可以使用readable-stream包来创建我们自己的可读对象流。
const through2 = require('through2');
const Readable = require('readable-stream').Readable;
const stream = Readable({objectMode: true}); /* 1 */
stream._read = () => {}; /* 2 */
setInterval(() => { /* 3 */
stream.push({
x: Math.random()
});
}, 100);
const getX = through2.obj((data, enc, cb) => { /* 4 */
cb(null, `${data.x.toString()}\n`);
});
stream.pipe(getX).pipe(process.stdout); /* 5 */
- 最重要的是在创建可读对象流的时候要将
objectMode设置为true。在这样做时,流能够通过管道传递JavaScript对象。不然它会认为是Buffer或者String。 - 每个流都需要一个
_read函数。这个函数会在数据块到达的时候触发。这是其它机制开始的位置,并将新内容推送到流。由于我们从外部推送数据,所以我们不需要这个功能,可以使它无效。 然而,可读流需要实现这一点,否则我们会报错误。 - 在这里,我们正在使用演示数据填充流。 每100毫秒,我们将一个随机数的另一个对象推送到我们的流。
- 由于我们想将对象流的结果传递给
process.stdout,而process.stdout只接受字符串,所以我们需要做个小的变换,我们从传递的JavaScript对象中提取属性。 - 我们创建一个管道。 我们可读的对象流将其所有数据传输到
getX,最后传输到process.stdout。
Node.js中流包的注意事项
您可能已经注意到,我们使用了通过NPM安装的不同流包。 不是很奇怪吗?
“Streams对于异步IO来说至关重要,它们不应该成为@nodejs核心的一部分吗? 是的没错。”
然而,流的核心在Node的旧的0.x版本的时候是不断变化的,这就是为什么社区在基本软件包的基础上加入并创建了一个坚实稳定的API。 使用语义版本控制,您可以确保流媒体生态系统与您的应用程序一起很好地移动。
足够的Demo演示,然我们正真的做些事
好!让我们做一个app去读取CVS数据并且保存到JSON中。我们想要使用对象流,因为在某些时候,我们可能需要根据用例来更改数据。由于流很强大,我们希望能够将结果以不同的格式输出。
首先我们先安装几个软件包:
const through2 = require('through2');
const fs = require('fs');
const split = require('split2');
- 我们已经了解了
through2。现在我们使用这个来创建转换。 fs包显然是用来读写文件的。厉害的是:它允许我们创建一个可读的流,这正是我们需要的。- 可能你不知道
fs.createReadStream的数据如何被拉入到内存中,所以split2包确保您可以逐行处理数据。 注意这个可变形的名称中的“2”。 它告诉你,它是语义版本的包装生态系统的一部分。
解析CVS
CSV非常适用于解析,因为它遵循非常容易理解的格式:逗号表示新的单元格。 一行表示新行。
简单。
在这个例子中,第一行始终是数据的标题。 所以我们想以一种特殊的方式对待第一行:它将为我们的JSON对象提供字段。
const parseCSV = () => {
let templateKeys = [];
let parseHeadline = true;
return through2.obj((data, enc, cb) => { /* 1 */
if (parseHeadline) {
templateKeys = data.toString().split(',');
parseHeadline = false;
return cb(null, null); /* 2 */
}
const entries = data.toString().split(',');
const obj = {};
templateKeys.forEach((el, index) => { /* 3 */
obj[el] = entries[index];
});
return cb(null, obj); /* 4 */
});
};
- 我们创建一个可变对象流。 注意
.obj方法。 即使您的输入数据只是字符串,如果要进一步触发对象,则需要对象流进行转换。 - 在这个代码块中,我们解析标题(逗号分隔)。 这将是我们的字段模板。 我们从流中删除这一行,这就是为什么我们传递的两个参数都是
null。 - 对于所有其他行,我们通过我们先前解析的字段来帮助创建一个对象。
- 我们将这个对象传递到下一个阶段。
更改和调整数据
一旦我们拥有可用的对象,我们可以更容易地转换数据。 删除属性,添加新的属性; 过滤,映射和缩小。 你喜欢的都可以。 对于这个例子,我们想保持简单:选择前10个条目:
const pickFirst10 = () => {
let cnt = 0;
return through2.obj((data, enc, cb) => {
if (cnt++ < 10) {
return cb(null, data);
}
return cb(null, null);
});
};
再次像前面的例子一样:传递回调的第二个参数的数据意味着我们将元素保留在流中。 传递null表示我们将数据丢弃。 这对过滤器至关重要!
保存到JSON
你知道JSON是什么意思?JavaScript对象。这太好了,因为我们有JavaScript对象,我们可以用字符串表示法来形容它们!
所以,我们想要处理流中通过的对象保存为一个对象,并将它们存储为一个字符串表示形式。 最先考虑到的是:JSON.stringify。
使用流时必须知道的一件重要的事情是,一旦对象(或Buffer数据)转换到下一个阶段,那么这个阶段就已经消失了。
这也意味着您可以将对象传递给一个可写流,不需要太多。 然而,必须有一个方法来做与收集数据不同的事情。 如果流中没有更多数据,每个转换会调用一次flush方法。
想想一个充满流体的水槽。
你不能选择它的每块数据块来进行再次分析。 但是,您可以将整个数据冲刷到下一个阶段。 这是我们正在做的下一个可变换到JSON:
const toJSON = () => {
let objs = [];
return through2.obj(function(data, enc, cb) {
objs.push(data); /* 1 */
cb(null, null);
}, function(cb) { /* 2 */
this.push(JSON.stringify(objs));
cb();
});
};
- 我们把传递过来的所有数据存放到数组里。 我们从我们的流中删除对象。
- 在第二个回调方法中,
flush方法,我们将收集的数据转换为JSON字符串。 使用this.push(注意经典函数符号),我们将这个新对象推送到我们的流进入下一个阶段。 在这个例子中,新的“对象”只是一个字符串。 与标准可写性兼容的东西!
例如,Gulp在使用链式调用行为时。 读取第一阶段的所有文件,然后将一个文件刷新到下一个阶段。
结合一切
到这里我又想到了函数式编程:后面的转换函数都是按行分开写的。它们完全可重用的不同场景,无论输入数据和输出格式。
唯一约束是CSV格式的(第一行是字段名),pickFirst10和toJSON需要JavaScript对象作为输入。并且把前10项转为JSON格式输出到控制台:
const stream = fs.createReadStream('sample.csv');
stream
.pipe(split())
.pipe(parseCSV())
.pipe(pickFirst10())
.pipe(toJSON())
.pipe(process.stdout);
完美!我们可以传输不同的可写流。在Node.js里,IO的核心是依赖流的。下面是一个HTTP服务器并把所有数据传输到互联网的例子:
const http = require('http');
// All from above
const stream = fs.createReadStream('sample.csv')
.pipe(split())
.pipe(parseCSV())
.pipe(pickFirst10())
.pipe(toJSON())
const server = http.createServer((req, res) => {
stream.pipe(res);
});
server.listen(8000);
这是Node.js流的一大优势所在。你可以异步的处理输入和输出,并且可以根据以依赖的步骤转换处理数据。对于对象流,你可以利用自己知道的部分去转换你的数据。
这是Gulp作为一个以流为基础的构建系统,但也是一个日常开发的好工具。
进一步阅读
如果你想深入了解流,我可以推荐一些资源:
- 《前端工具之Gulo,Bower和Yeoman》书中有一些章节是讲流工具的像合并流以及后面有章节讲转移流。
- Fettblog 我的博客有很多关于
Gulp和Gulp插件的文章。因为所有Gulp插件被编写为对象,你可以学习写一个或从中学习到其它东西。 - Substack的一本关于流的电子书。了解流的原理。
- Rod Vagg 对流核心的讲解。有点老,但是依然是很不错的:Rod Vagg 解释为什么使用流类型的NPM包。
原文:https://community.risingstack.com/the-definitive-guide-to-object-streams-in-node-js/
译者:Jin