Node.js源码解析--http.js模块
http模块处理的是Node.js的网络请求。在Node.js里面主要依赖的有net.js模块,底层依赖http_parser库函数。
总之就一句话:http = tcp服务器 + callback函数(里面最重要的就是http_parser)
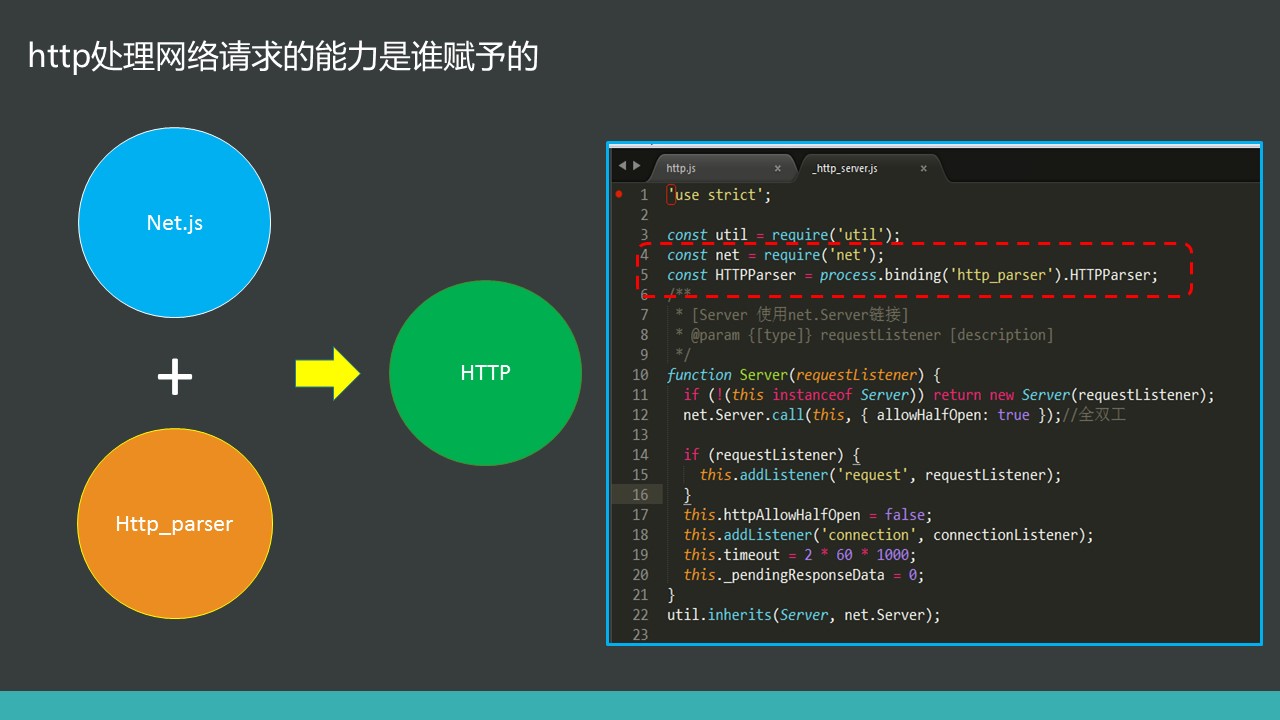
http模块的主要功能:创建web服务器以及创建客户端请求。
http.Server
Server对象其实继承于net.Server,只不过connection监听函数不同而已。还有就是http.Server可以监听request。
当客户端发起请求时,首先会进行TCP连接。连接成功会触发服务器端的connection监听事件。到这一步其实还没有http模块啥事。
http模块要做的就处理接下来与客户端进行数据交换的socket实例对象。客户端发送的get或者post等请求都会发送到这个socket 上,
那么怎样才能正确的解析http请求,这就是Node.js依赖C/C++http_parser库的原因。http_parser是一个第三方的库。http模块的connectionLister函数(也就是connection事件的监听函数)里面会从parsers里面取出一个空闲的http_parser实例对象,
使用这个http_parser实例对象解析当前socket的连接请求。http_parser实例对象提供了解析数据的每个阶段的回调函数。
http_parser解析完header之后,就会触发request事件,那body数据放到哪里呢。其实body数据会一直放到流里面,直到用户使用data事件接收数据。
也就是说,触发request的时候,body并不会被解析。
parser 实例
parser实例的每个周期都有回调函数。
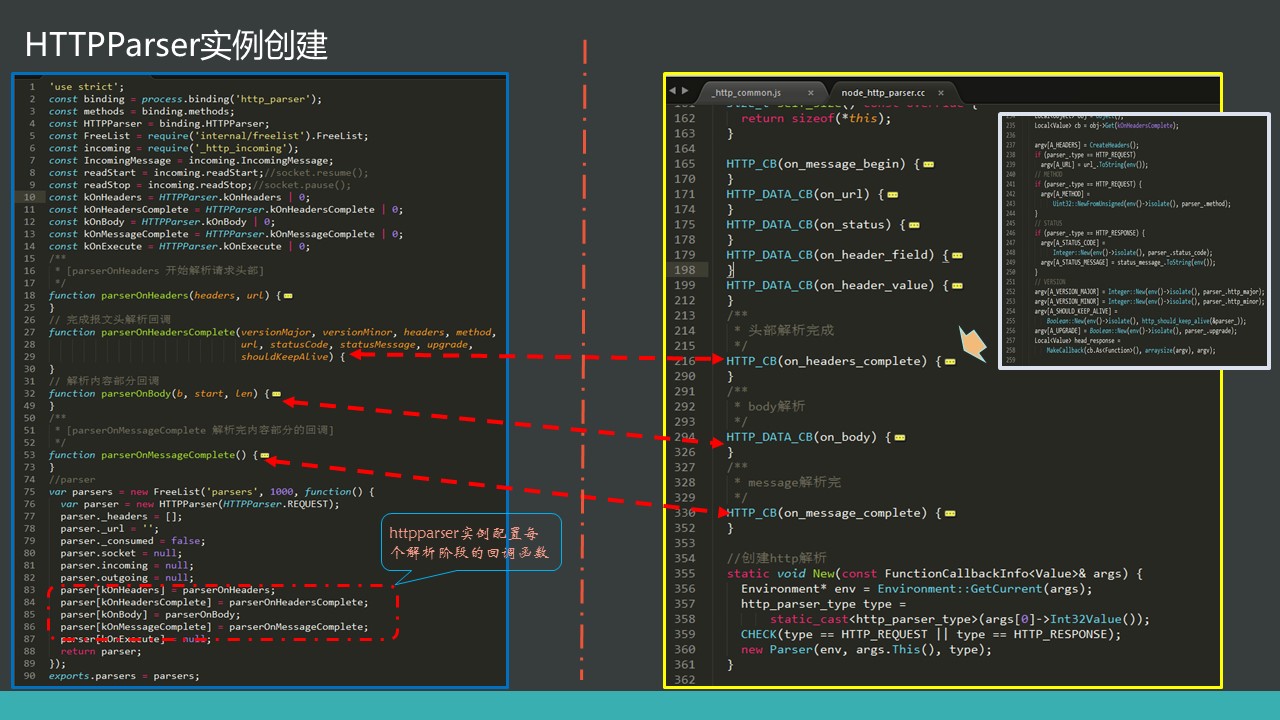
最主要的就是parserOnHeadersComplete,请求头解析完成后会触发这个函数。parserOnMessageComplete是接收body完成后触发。最终
会触发end事件。表明数据接收完成。
var parsers = new FreeList('parsers', 1000, function() {
var parser = new HTTPParser(HTTPParser.REQUEST);
parser._headers = [];
parser._url = '';
parser._consumed = false;
parser.socket = null;
parser.incoming = null;
parser.outgoing = null;
parser[kOnHeaders] = parserOnHeaders;
parser[kOnHeadersComplete] = parserOnHeadersComplete;
parser[kOnBody] = parserOnBody;
parser[kOnMessageComplete] = parserOnMessageComplete;
parser[kOnExecute] = null;
return parser;
});
exports.parsers = parsers;
http默认创建了1000个http_parser实例。每当有http请求请求连接成功后,都会从数组中取出一个http_parser分配给当前socket。1000个分配完,则会创建新的。
var parser = parsers.alloc();//拿出空闲的序列化对象
parser.reinitialize(HTTPParser.REQUEST);//重新初始化请求头为REQUEST
parser.socket = socket;
socket.parser = parser;
parser.incoming = null;
if (typeof this.maxHeadersCount === 'number') {
parser.maxHeaderPairs = this.maxHeadersCount << 1;
} else {
parser.maxHeaderPairs = 2000;
}
socket.addListener('error', socketOnError);
socket.addListener('close', serverSocketCloseListener);
parser.onIncoming = parserOnIncoming;
socket.on('end', socketOnEnd);
socket.on('data', socketOnData);
exports.FreeList.prototype.alloc = function() {
return this.list.length ? this.list.pop() :
this.constructor.apply(this, arguments);
};
c/c++模块解析完请求头会执行回调函数parserOnHeadersComplete, 当不是udp类型的请求时,执行onIncoming,触发request事件。
// 完成报文头解析回调
function parserOnHeadersComplete(versionMajor, versionMinor, headers, method,
url, statusCode, statusMessage, upgrade,
shouldKeepAlive) {
var parser = this;
//创建请求报文实例
parser.incoming = new IncomingMessage(parser.socket);
parser.incoming.httpVersionMajor = versionMajor;
parser.incoming.httpVersionMinor = versionMinor;
parser.incoming.httpVersion = versionMajor + '.' + versionMinor;
parser.incoming.url = url;
var n = headers.length;
// If parser.maxHeaderPairs <= 0 assume that there's no limit.
if (parser.maxHeaderPairs > 0)
n = Math.min(n, parser.maxHeaderPairs);
parser.incoming._addHeaderLines(headers, n);//报文头参数设置
if (typeof method === 'number') {
// server only
parser.incoming.method = methods[method];
} else {
// client only
parser.incoming.statusCode = statusCode;
parser.incoming.statusMessage = statusMessage;
}
if (upgrade && parser.outgoing !== null && !parser.outgoing.upgrading) {
upgrade = false;
}
parser.incoming.upgrade = upgrade;
if (!upgrade) {
skipBody = parser.onIncoming(parser.incoming, shouldKeepAlive);
}
当头部解析完成会触发request:
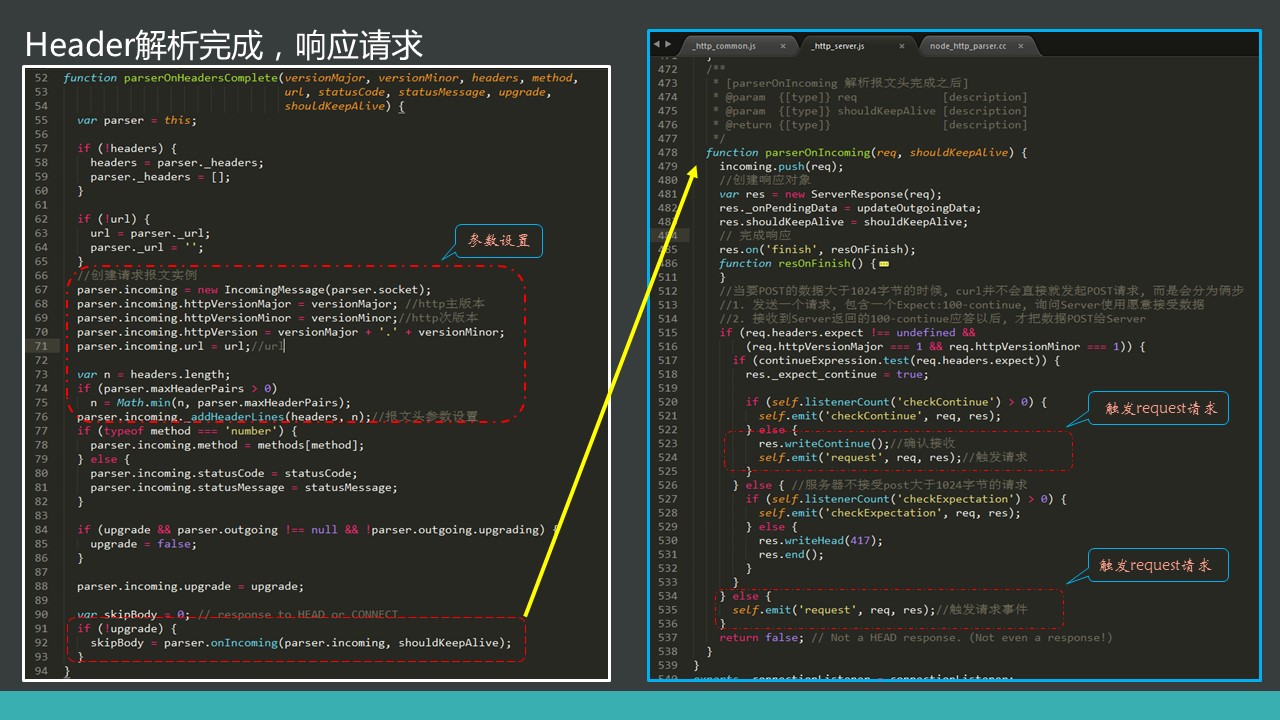
parserOnMessageComplete 数据解析完成回调函数。会触发end事件,表示数据已经解析完成。
/**
* [parserOnMessageComplete 解析完内容部分的回调]
* @return {[type]} [description]
*/
function parserOnMessageComplete() {
var parser = this;
var stream = parser.incoming;
if (stream) {
stream.complete = true;
// Emit any trailing headers.
var headers = parser._headers;
if (headers) {
parser.incoming._addHeaderLines(headers, headers.length);
parser._headers = [];
parser._url = '';
}
// For emit end event
stream.push(null);
}
// force to read the next incoming message
readStart(parser.socket);//开始读取内容
}
parser.onIncoming(parser.incoming, shouldKeepAlive)
请求头解析完回调函数。会触发request事件。
/**
* [parserOnIncoming 解析报文头完成之后]
* @param {[type]} req [description]
* @param {[type]} shouldKeepAlive [description]
* @return {[type]} [description]
*/
function parserOnIncoming(req, shouldKeepAlive) {
incoming.push(req);
//创建响应对象
var res = new ServerResponse(req);
res._onPendingData = updateOutgoingData;
res.shouldKeepAlive = shouldKeepAlive;
//当要POST的数据大于1024字节的时候, curl并不会直接就发起POST请求, 而是会分为俩步
//1. 发送一个请求, 包含一个Expect:100-continue, 询问Server使用愿意接受数据
//2. 接收到Server返回的100-continue应答以后, 才把数据POST给Server
if (req.headers.expect !== undefined &&
(req.httpVersionMajor === 1 && req.httpVersionMinor === 1)) {
if (continueExpression.test(req.headers.expect)) {
res._expect_continue = true;
if (self.listenerCount('checkContinue') > 0) {
self.emit('checkContinue', req, res);
} else {
res.writeContinue();//确认接收
self.emit('request', req, res);//触发请求
}
} else { //服务器不接受post大于1024字节的请求
if (self.listenerCount('checkExpectation') > 0) {
self.emit('checkExpectation', req, res);
} else {
res.writeHead(417);
res.end();
}
}
} else {
self.emit('request', req, res);//触发请求事件
}
}
self.emit('request', req, res) 会触发request请求。那么整个请求阶段就结束,剩下的就是reeponse需要做的事了。
简单的http服务器
const http = require('http');
http.createServer((req , res)=>{
console.log('request here.');
}).listen(3000,'127.0.0.1');
如果需要解析body那么我们需要添加接收body的data事件和end事件,保证在接收数据完成后再对数据进行操作。
const http = require('http');
http.createServer((req , res)=>{
console.log('request here.');
let data = '';
req.on('data',(chunk)=>{
data += chunk;
});
req.on('end',()=>{
console.log('data:',data);
});
}).listen(3000,'127.0.0.1');
执行案例:
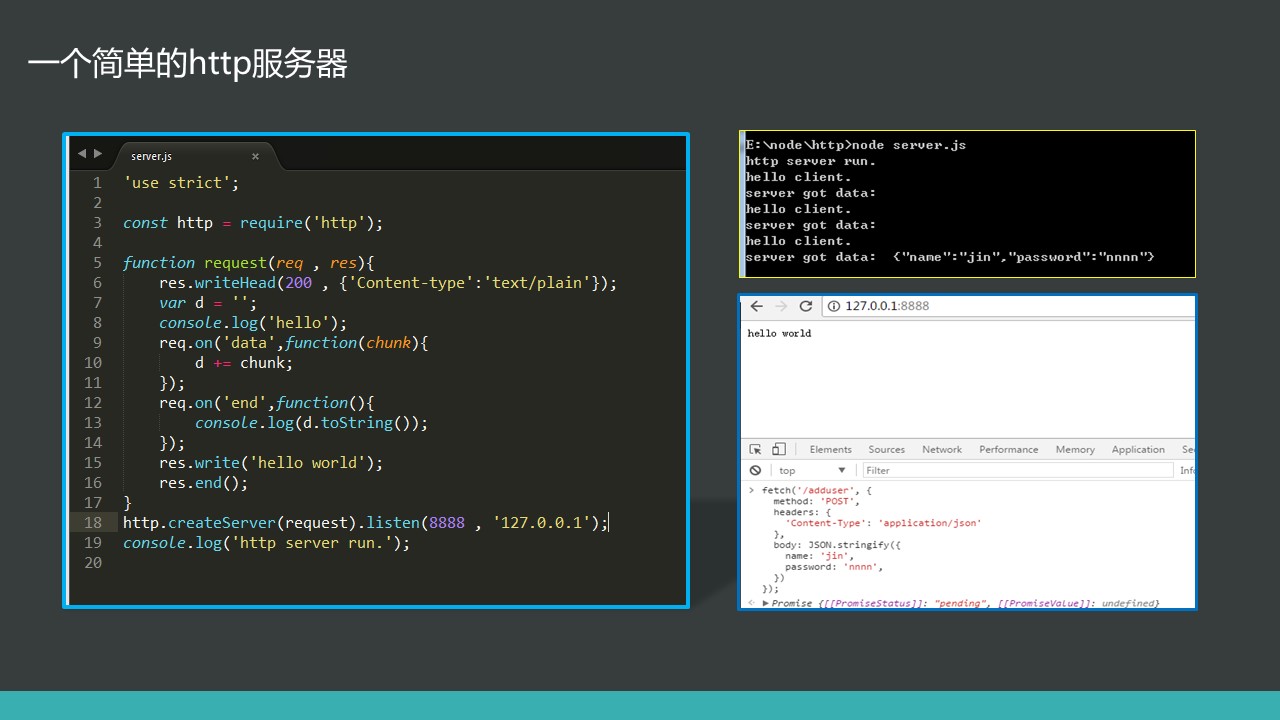
图说真相
处理一次http请求从大的方面来说,是这个样子的:
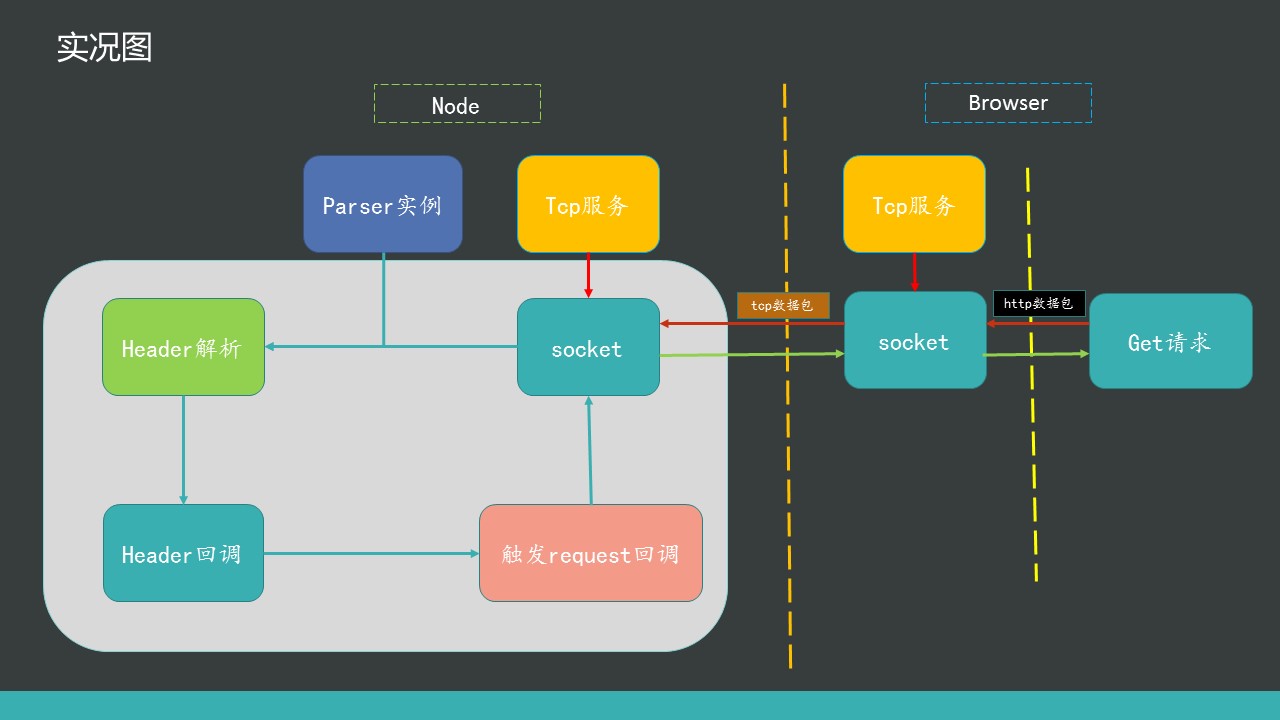
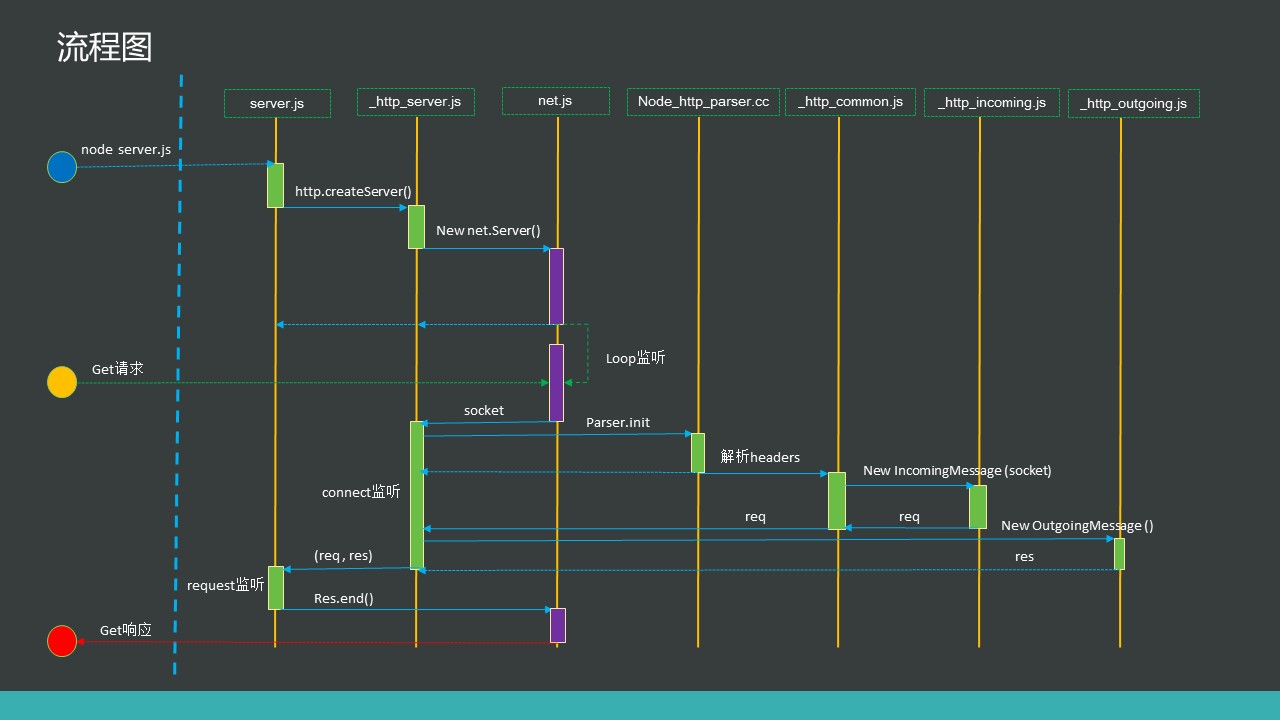
处理一次http请求从代码层面来说,是这个样子的:
我们平时使用的框架如express和koa都会有一个bodyparser中间件。这个中间件的作用就是为我们解析body然后插入到request对象上。